머신러닝이 뭘까?
머신러닝은 그냥 컴퓨터한테 학습시키는 것을 몽땅 머신러닝이라고 한다.
더 다듬어서말하자면 컴퓨터가 수학계산을 풀 수 있게 데이터셋을 이용해 학습시키는 행위이다.
조금더 구체적으로 설명하자면 과거의 토익점수를 토대로 다음번 토익시험의 점수을 예측하는 것이다.
대충 수식을 세우자면 아래와 같다.
토익점수 = 1월점수 x A + 2월점수 x B
A = 0.4, B = 0.6
A와 B는 위에 설정한 값으로 추론하였을때 내가 설정한 값과 1,2분기 데이터의 값을 비교해서
오차가 최소화 되는 A와 B값을 찾으면 머신러닝이다.
여기서 A, B 를 weight 가중치라고 부르고 보통 줄여서 w1, w2라고 한다.
즉 주어진 입력값을 함수에넣고 예측된결과를 찾을수 있게 가중치(weight)값을 찾게 시키는 것이 머신러닝이라 할수있겠다.
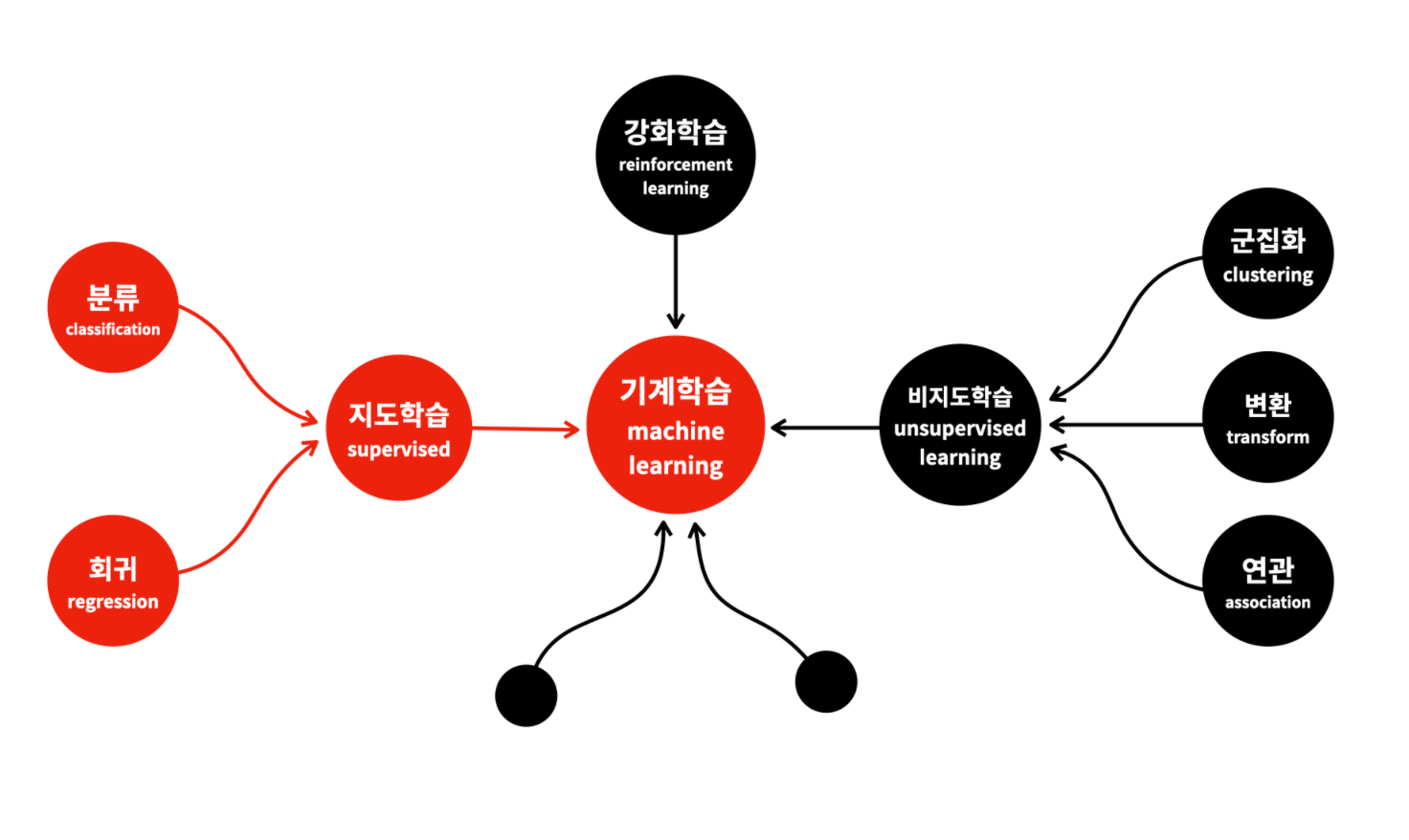
머신러닝 유형
머신러닝은 입력 데이터가 무엇인지에 따라 크게 다음 3가지로 분류된다.
- 지도 학습 (supervised learning)
- 비지도 학습 (unsupervised learning)
- 강화 학습 (reinforcement learning)
이처럼 머신러닝을 활용하여 데이터에 대한 적절한 알고리즘을 이용했을 때 아직 접하지 못한 새로운 것을 발견할 수 있다.
사용예
머신러닝으로 풀 수 있는 문제들은 다음과같다.
- 다양한 성능 지표를 기반으로 회사의 내년수익을 예측하기 : 회귀(regression) 숫자 이용
- 챗봇 개인 비서 만들기 : NLU와 질문대답모듈 이용
- 신용카드 부정 거래 감지하기 : 이상치 탐지
- 구매이력을 기반으로 고객을 나누고 각 집합마다 다른 마케팅 전략 계획하기 : 군집작업 이용
- 마스크를 착용했는지 판별하기
- 긴 문서를 자동으로 요약하기 : NLP(natural language processing) 이용
- 자동으로 뉴스기사를 분류하기 : NLP(natural language processing) 이용
- 토론 포럼에서 부정적인 코멘트를 자동으로 구분하기 : NLP(natural language processing) 이용
- 음성명령에 반응하는 앱 : RNN, CNN, 트랜스포머 사용
- 고차원의 복잡한 데이터셋을 그래프로 표현하기 : 차원축소(dimensionality reduction) 이용
머신러닝의 단점
- 데이터에 너무 의존적이다.
- 학습시 최적의결과를 도출하기위해 만들어진 모델은 데이터 적용시 과적합 되기 쉽다.
- 머신러닝 알고리즘으로 만들어진 결과값에 대한 논리적인 이해가 어려울 수 있어서 마치 블랙박스와 같다고 할 수있다.
- 데이터만 집어 넣으면 자동으로 최적화된 결과를 도출하지 않는다. 특정 경우는 개발자가 직접 만든 코드보다 성능이 떨어진다.
- 모델을 개선하기 위한 노력이 끊이없이 필요하기 때문에 데이터의 특성을 파악하고 최적의 알고리즘과 파라미터를 구성할 수 있는 고급 능력이 필요하다.